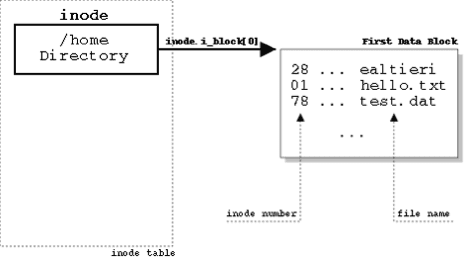
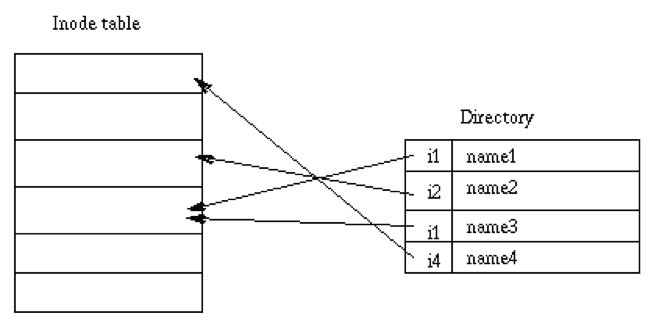
As in any multi-step operation, failures may occur at any point. The process may crash, the disk may lose the update, etc. These failures could be evidenced in the form of the operating system not showing the created file, an inability to create a file with the same name, or a resource leak.
There are two standard ways to deal with such inconsistencies:
- Use transactional mechanisms to update multiple metadata objects. These transactions typically adhere to ACID guarantees (Atomicity, Consistency, Isolation, Durability). So general failures arising out of a process- or system crash are handled cleanly in transactional systems. The entire transaction is rolled back or rolled forward, using redo/undo transaction logging.
- Use ordered updates. Here, multiple updates are ordered in such a way that at any point, a partial list of updates is safe (from an overall system behavior perspective). But, periodically, the incomplete or partial updates need to be cleansed from a space perspective. (For more on ordered updates, see the seminal paper, Soft Updates, from the ACM Transactions on Computer Systems, Vol. 18, No. 2, May 2000.)
For example, to illustrate a “safe” order of updates, as part of adding a new data block to a file in Druva Storage:
- The block is stored persistently,
- Dedupe indexes are created, and
- A block map of the file is updated.
Traditionally, file systems have deployed offline utilities such as fsck (file system consistency check) or chkdsk to fix such metadata inconsistencies and to restore sanity. These tools are mostly off-line, which implies down time or outage for the file system. Depending on the circumstances, that may be an extended outage – which can cause user and IT upsets.
Naturally, we felt we needed to create a better answer.
Druva Storage
Druva products deploy our own file system, called Druva cloud file system. The key features of the Druva cloud file system are:
- Source-side data de-duplication (dedupe)
- Continuous data protection
- Compressed and encrypted data storage in transit and at rest
- Policy-based data retention
Druva cloud file system addresses several key concerns:
Durability
Druva cloud file system, hosted on Amazon public cloud, uses AWS S3 to store data. Amazon S3 is designed to provide 99.99999% durability of objects. Also, Amazon S3 is designed to sustain the concurrent loss of data in two facilities.
Druva cloud file system also uses the AWS DynamoDB service to manage its file-system metadata. Amazon DynamoDB synchronously replicates data across three facilities within an AWS Region.
When inSync is hosted on-premise, Druva cloud file system uses the local file system to store data and an embedded BerkeleyDB database engine to manage metadata. For on-premise data and database reliability, we rely on underlying disk subsystem reliability mechanisms (that is, RAID). It’s also possible to achieve redundancy via the dual-destination backup feature in inSync.
Availability
The Druva inSync cloud service is hosted on Amazon EC2 instances and accessible over WAN. It hosts hundreds to thousands of devices and backups, which are happening across the globe. This scale has an implication that extended outages for cleaning up inconsistencies anywhere in the system are simply not acceptable. Hence it’s very important to be available at all times. Failover is seamless, despite EC2 failures.
On-premise Druva inSync runs inside our customers’ data centers. It’s possible to achieve availability with the aforementioned dual-destination backup feature. Availability is no less of a concern for on-premise deployments; again, tens of thousands of devices are backed up regularly to Druva inSync.
Self-Healing Storage
Druva cloud file system may also face crashes, in the form of process failure, network disconnects, etc. In addition, loss of database entries can happen due to disk corruption or other failures. At times, anti-virus software can create foul play if it’s misconfigured. At such large scales, bringing down services to regularly detect and correct inconsistencies is simply not feasible. This brings us to the idea of self-healing storage.
It’s important for inSync that Druva cloud file system continues to serve both backup and restore requests, despite any possible storage inconsistencies. That’s what we’re selling, after all.
Our most common use case is when a laptop is dead and the user wants his data back as soon as possible. The last thing anyone wants to see under such circumstances is restore failures. To address this restorability concern, as a regular inSync maintenance procedure, a restore is simulated for the latest snapshot of each device. This guarantees that if a restore is attempted for the snapshot it won’t fail due to any kind of metadata inconsistencies.
If inconsistency is detected during the simulated restore process, it gets purged. This ensures that the snapshot is restorable, though it may miss a few files. Also, inSync does a full backup to follow that inconsistency report, to guarantee that the subsequent snapshot will be clean and fully restorable. Thus, Druva storage ensures restorable snapshots for the mobile devices or laptops being backed up.
There are other possible inconsistencies which may not impact the restore process, but may prevent compaction or incremental backups of the device. To detect and fix them, Druva cloud file system has its own fsck functionality. Its responsibility is to detect, report, and fix inconsistencies.
Both of these mechanisms run in the background during off-peak hours, as a regular, scheduled maintenance procedure.
At the scale at which Druva storage operates, it’s almost impossible to manually detect and fix metadata inconsistencies. Having it automated and self-healing is the only way our serviceability could scale at these levels. And we at Druva understand it well!
Interesting in getting to know Druva? Find out more by checking out these popular resources:
Download our FREE executive brief on addressing data sprawl, below!