At Druva we perform more than 4 million backups every single day. As data continues to be the driving force for any organization, we are committed to developing innovative capabilities that are designed to benefit our customers and their data.
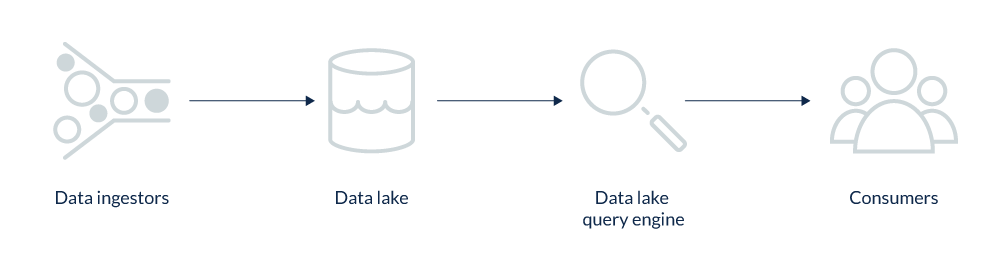
Due to the billions of backup events generated by the sheer volume and scale of unstructured data that we backup, it’s also important to have a central storage pool for each customer that can enable analytics and insights. Furthermore, it’s critical to deploy a primary query engine that is compatible with the repository to enable faster queries at scale.
Introducing Druva data lake
Druva data lake is designed to be the centerpiece of the Druva data architecture. By instrumenting the data lake, it is now possible to have a central place for data that can be used by Druva products for analytics requirements. This data lake can also be utilized by data science and machine learning teams for faster experiments.
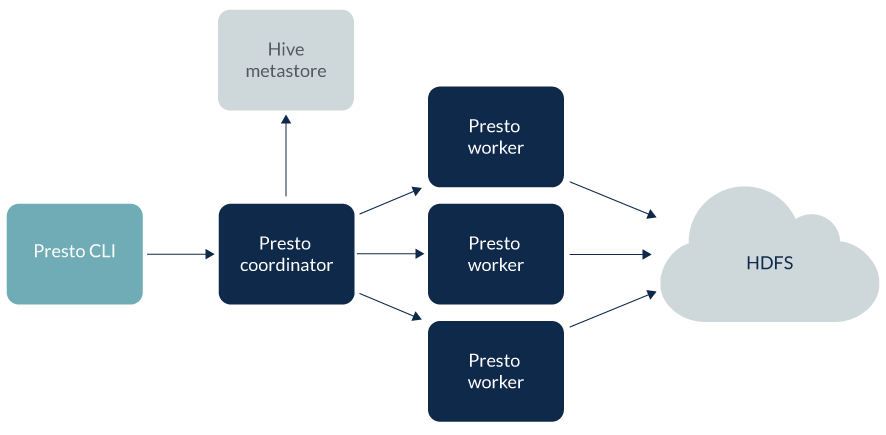
We use Amazon Web Services (AWS) S3 as a storage layer for the data lake which enables cost optimization for data compared to Hadoop HDFS-based solution. In addition, we also use Apache Parquet file format to store data, which is a columnar storage format for efficient data storage. Our data is partitioned based on hour-value to support range queries.
The data lake holds backup events and is consumed by various internal applications. One of the applications that we will discuss further is our ‘backup metadata search’ application.
Enabling data lake access to internal applications
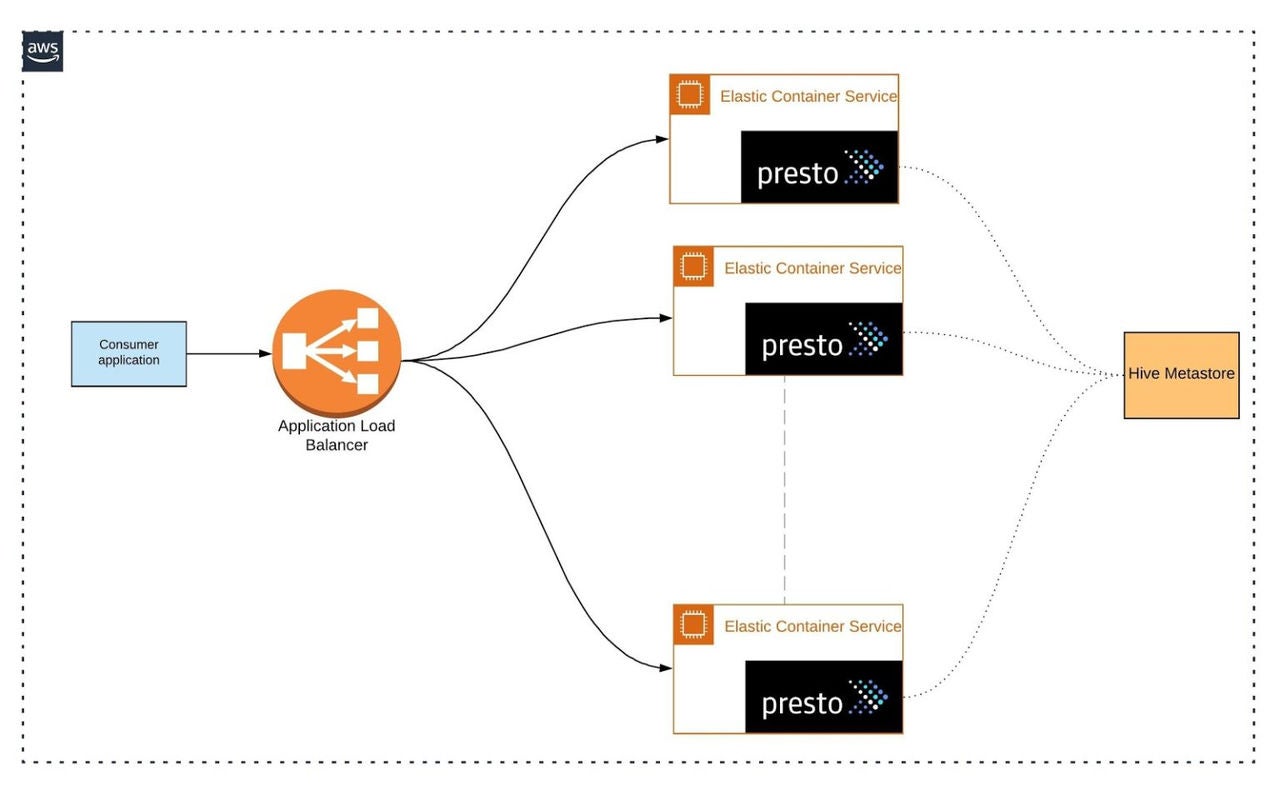
To access the data lake, we provide an abstraction to consumer applications, which is a query engine between consumers and the data lake.