Cache Workflow
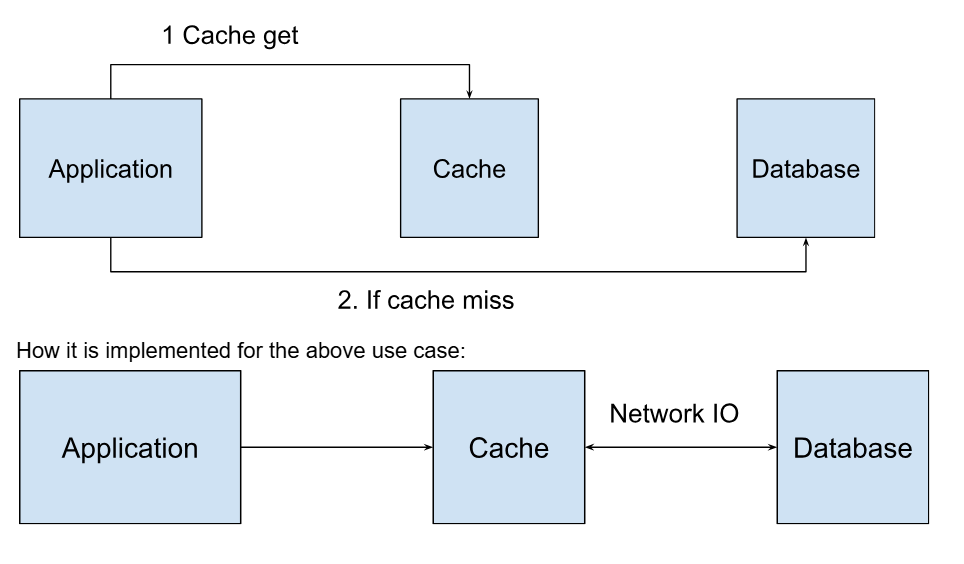
When a cache get request is initiated, if the requested data is present in the cache, it is swiftly returned, enhancing response times significantly. If data is not present in the cache, a function call will be made to get the data from the server. Let's look at how it is efficiently managed using inflight requests and careful orchestration of data flow.
Managing Inflight Requests
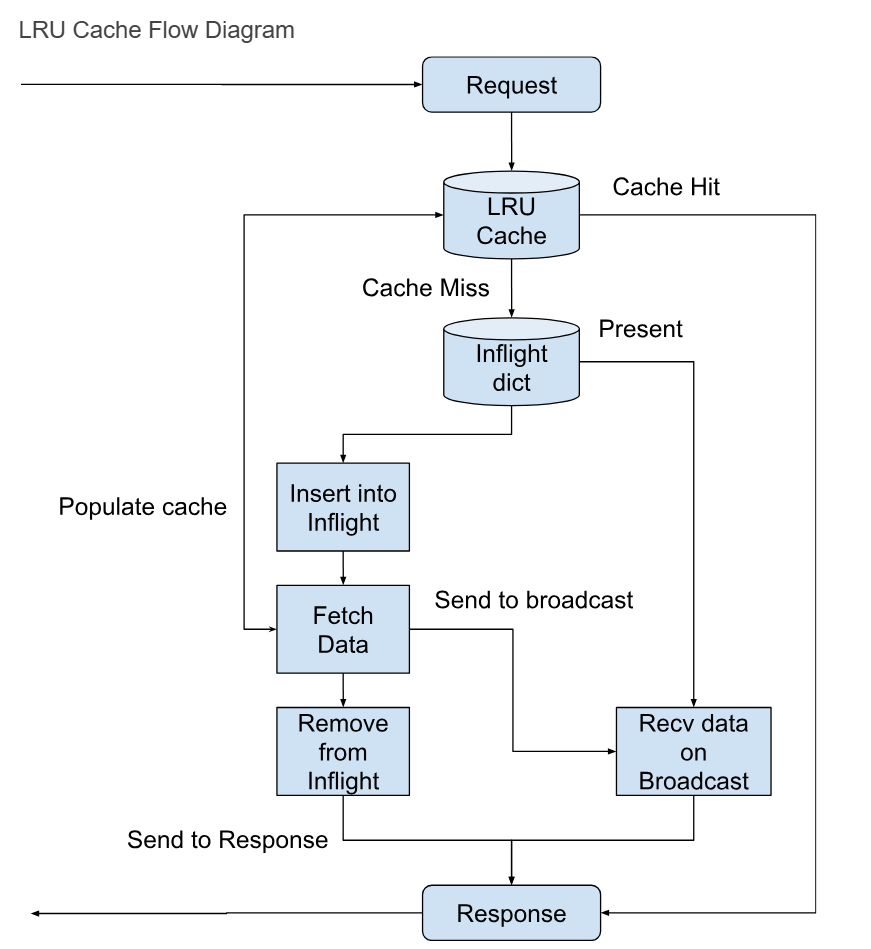
The inflight requests dictionary serves as a tracking mechanism. When a cache miss happens, this dictionary is consulted. If another worker is already fetching the requested data, the new request is not immediately routed to the server. Instead, the requesting worker is placed in a waiting state, anticipating the data to arrive shortly.
In this setup, a clever utilization of Rust synchronization primitives comes into play. Here, once data is available the fetching worker communicates it back to all waiting workers simultaneously.
Efficient Orchestration
Once an entry is made in the inflight requests dictionary, the fetching process begins. The first worker initiates a call to the server, aiming to retrieve the requested data. Simultaneously, any other workers waiting for the same data are blocked, waiting for the first worker to make the information available.
Upon successful retrieval of data by the first worker, it will
Populate the cache, ensuring that subsequent requests for the same data can be handled from the cache.
Remove the entry from the inflight requests dictionary and send the data so all waiting workers will receive it.
Send data to the main request.
Handling Failures
In the event of a failure during the data-fetching process, a well-designed fail-safe mechanism comes into action. If the function call to the server encounters an error, all waiting workers are promptly notified with the error information. This ensures that errors are handled gracefully.