Introduction
Druva uses agents to back up data from different data source types such as VMs, NAS, file servers, and more. With different data types from each source, each agent was built from the ground up to cater to the requirement of the data source. This introduced some challenges in the development and maintenance of these agents.
That’s why we recently built a component to make the agent development process more streamlined. We named these components data movers. It includes generic business logic for these tasks and offers a set of interfaces that can be customized for specific workloads. This blog post talks about what data movers are and explains why and how we built its different variants.
Why we needed data movers?
The motive behind building the data movers component was to reduce duplication of code and facilitate better maintenance, provide clean and consistent interfaces for future development, and make it easier to incorporate new features. The data movers component aimed to improve the efficiency of the agents. By integrating their implementation with the data movers, developers can easily create and deploy backup and restore agents.
Previously, Druva agents were written using Python. As we were in the process of upgrading our architecture, we decided to write the data mover component in Go instead of Python. There are several reasons for this decision: Go is faster and more efficient, has built-in support for concurrency using goroutines, and its static typing means maintenance is easier. These benefits made Go the perfect fit for all our use cases.
Workload variations
Druva protects data for a variety of workload categories, such as virtualization, databases, NAS boxes, file servers, and SaaS applications. These workloads do vary in terms of the number and size of files being backed up, the nature of data, the methods used to identify changes or blocks of data, and the methods used to coordinate backup and restore tasks. In order to accommodate the wide range of requirements for these different workloads, we developed a few variations of the data mover component. Each variation was tailored for a workload category. By using these specialized data movers, Druva is able to provide comprehensive support for a wide range of workloads.
We have developed the following variants of data movers:
Data movers for Virtual Workloads
This data mover is designed to work with different types of virtualized workloads where data is read through specialized APIs. Virtual environments provide Change Block Tracking (CBT) APIs to identify data blocks that have changed across two snapshots. Backup and restore tasks for these workloads are typically coordinated through a Druva agent that is installed on a proxy device. Examples of workloads that fall into this category include VMware, AHV, HyperV, and Amazon EC2.
Data mover for Databases
This data mover is optimized for workloads that involve databases and can operate in one or multiple modes such as full backups, change-log-based backups, and differential backups. These workloads typically provide push-based streams for changed blocks and require a Druva library to be plugged into the application for orchestration. Examples of workloads that fall into this category include Oracle and SAP Hana.
Data mover for File Servers/NAS
This data mover is designed to work with fileserver data such as NAS shares or filesystem folders. It can use either traversal-based or more optimized application-specific methods to identify changes, depending on the specific workload. Backup and restore tasks for these workloads are typically coordinated through a Druva agent residing on the source or a proxy. Examples of workloads that fall into this category include NAS servers and Linux/Windows-based file servers.
The rest of this article is going to be focused on the first combination which is the data mover for virtual workloads.
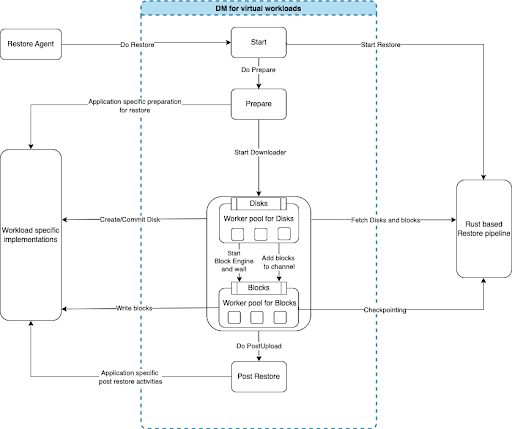
Responsibilities of the data mover for virtual workloads
- Orchestration of the backup and restore jobs.
- Traversal through the virtual machine disks for change identification.
- Concurrency management for parallel file IO and block IO tuned for maximum performance.
- Local state management for detecting and correcting inconsistencies that can arise due to cases such as job failures.
- Provision to store metadata separately to help with subsequent backup and restore jobs. Metadata like the VM layout for restoration, information related to incremental backups, and restore view for representation purposes among others.
- Handling for thin and thick provisioned disks.
- Stat management.
- Error handling involves appropriate actions on a case-by-case basis.
- Improve performance for backup/restore pipeline for batching, compression/decompression, and checksums. (This is a high-performance library developed by Druva. Read more about this on our Achieving >1TB/hr backup speed by implementing the core client-side data pipeline in Rust blog.)
- Provide generic interfaces for application-specific implementations such as:
- Snapshotting during backup
- Creation of VMs during restore
- Attaching of disks to VMs during restore
- Identification of changed blocks
- Reading of data blocks during backups
- Writing of data blocks during restore
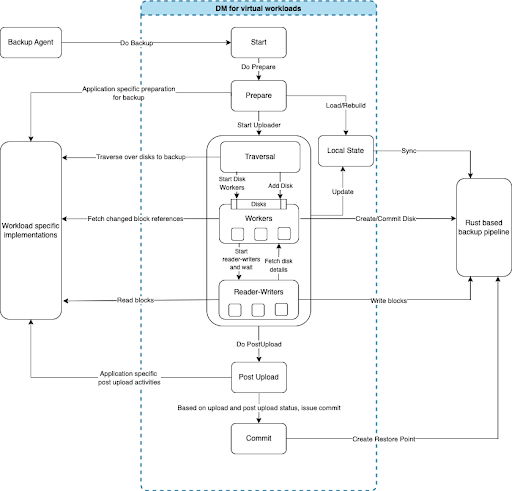
Backup workflow
The central component depicted within the blue dotted lines represents the common data mover component that is used to manage and coordinate backup tasks for virtual workloads. It is responsible for orchestrating the entire backup workflow, which includes preparing the source data, processing files and blocks for backup through multiple goroutine engines, completing post-upload processing, and creating the snapshot. It also maintains a local state to identify modifications to a VM such as the addition or removal of disks and to correct inconsistencies in the snapshot data. To perform operations specific to a workload, such as snapshotting, traversing through disks, and reading blocks, the data mover offers interfaces that the target workload must implement.