When do you need a big data pipeline?
The term “big data” is typically used to emphasize the volume of data for a data pipeline use case. The volume can be described as events per second in a streaming data pipeline, or the size of data in a batch-based data pipeline. Terms like “big data pipeline,” “big data ETL pipeline,” or “big data ETL” are used interchangeably.
Typically, if the data is only a few GBs, a data processing/transformation step can be as simple as a Python script, and it will typically handle transformations, like aggregations, very easily. However, if the data volume is in hundreds of GBs and constantly growing, the data processing engine should be capable of handling such a volume. Hence, data processing becomes a crucial part of the process to handle these huge volumes of data.
Data processing in a big data pipeline
Data processing can include simple steps like data type checks, type conversions, and complex aggregations such as grouping, or joins between two datasets. When these operations are applied on hundreds of GBs of data, choosing a right data processing engine becomes crucial. Below are some of many data processing engines available for large scale data processing.
- Apache Hadoop MapReduce
- MapReduce is the processing layer of the Hadoop ecosystem. It is a highly scalable distributed data processing framework. It is comparatively slower for large datasets as it tries to write data to disk as a part of the MapReduce process.
- Apache Spark
- Spark focuses on in-memory computations and leverages its distributed data structure, also known as RDD (resilient distributed dataset). Spark includes batch processing, stream processing, and machine learning capabilities. Taking batch processing into consideration, it is comparatively faster than the traditional MapReduce approach. Hence, Spark is popular for distributed batch processing.
- Apache Flink
- Flink is based on distributed stream processing, and is usually preferred for stream-based data pipelines.
Almost all of these available large-scale data processing engines are based on the concept of distributed computing and are capable of handling huge amounts of data.
Data pipeline use cases
We will now discuss two big data pipeline use cases for the Druva data lake which give an idea of the different steps in building scalable data pipelines.
Data lake formation
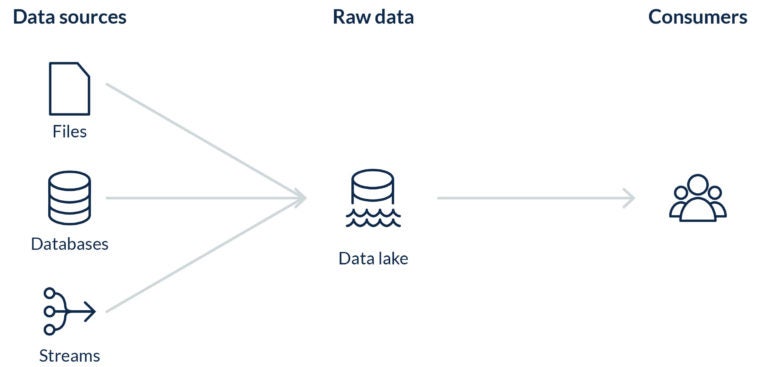
The Druva data lake holds hundreds of TBs of data which can be structured or semi-structured. All this data comes from various sources including files, streams, databases, and more.
To ingest all this data into the data lake, a data pipeline is created from each source. Some of these pipelines have a transformation step, for example, a file based data source. Whereas some of these pipelines just write the data as it is, for example, a telemetry stream which writes data to the lake directly from various applications.
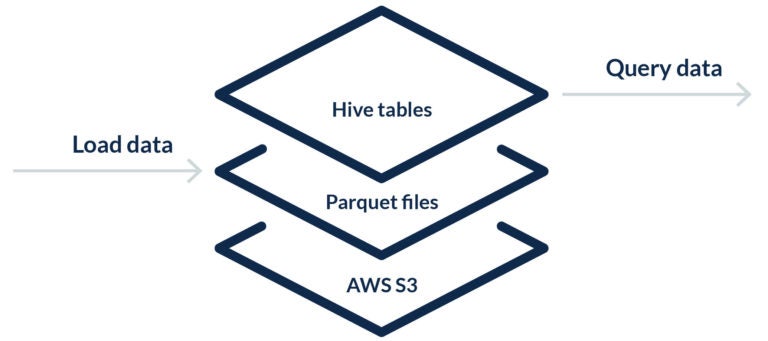
An ETL process per data source is used to transform different data formats into a single columnar file format, usually Apache Parquet. Streaming sources usually load the data directly to the data lake without a transformation step, for example an AWS Kinesis stream.
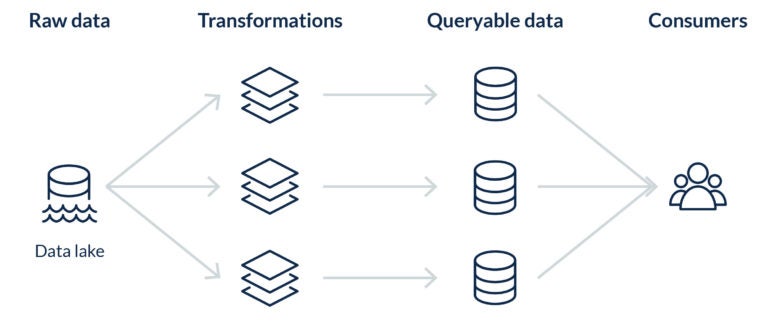
Below are the three key steps of an ETL job.
- Extract — Data is extracted from a source location, such as a file system or object store like Amazon S3
- Transform — Extracted data is then transformed into the desired structure/schema for the destination system
- Load — Finally, transformed data is loaded into the destination system's file format, usually a columnar file format